
Что каждый программист должен знать о памяти
Что каждый программист должен знать о памяти [2007] Ulrich Drepper
A Solid Average
Нужно ли её читать — вопрос. Уж точно не “каждому”.
Книге уже 17 лет, но информация актуальна: устройство памяти и кэшей практически не изменилось. Разве L3 уже не диковинка.
На примерах кода показаны последствия изменения рабочего набора данных, количества потоков, расположения критического слова. Автор показывает, как влияют размеры кэша/TLB, количество промахов и переключений контекста, механизм предварительной загрузки.
Читается сухо, но альтернатив по теме я не встречал. Если знаете что-то похожее — буду благодарен за ссылки.
Я бы советовал читать выборочно: части 2, 3 и 5 — “Кэш-память процессора”, “Виртуальная память”, “Оптимизация кэша”. Возможно, начало 6 части и 7 — “Мультипотоковая оптимизация”, “Инструменты”.
Остальное мало применимо, специфично. Например, я в своей работе не привязываю потоки к ядру и не ориентируюсь на NUMA архитектуру. Да и часть инструментов профилирования можно заменить на современный подход.
Английская версия книги доступна по ссылке: What every programmer should know about memory
Практика
Не удержался и провёл эксперимент на своей машине: проверял, можно ли определить размер кэшей с помощью кода — можно.
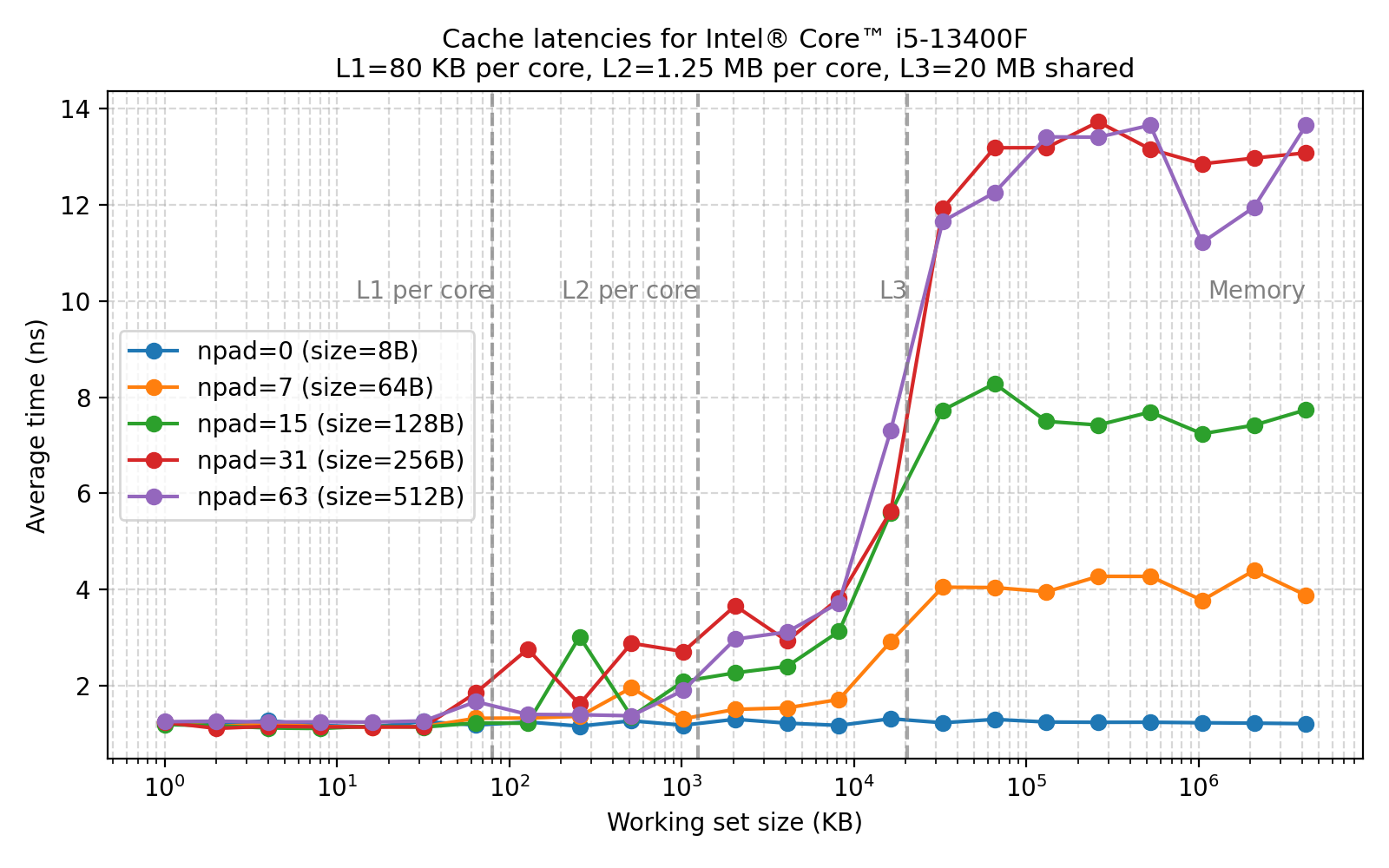
Визуализировал всё на Python — можно попросить любой AI инструмент, он этот код напишет на раз два. Впрочем, и код ниже был написан с помощью AI - в нём нет ничего необычного, разве пара моментов с madvise, разогревом и black_box, чтобы компилятор ничего не оптимизировал.
Программа создаёт связный список в памяти, пробегает его несколько раз и измеряет среднюю задержку доступа. Таким образом можно наглядно увидеть влияние кэширования и размера рабочего набора.
#[repr(C)]
struct Node {
next: *mut Node,
_pad: [usize; 0],
}
struct LinkedListArena {
ptr: *mut u8,
layout: Layout,
head: *mut Node,
num_elements: usize,
total_bytes: usize,
}
impl LinkedListArena {
fn new(num_elements: usize, element_size: usize) -> Self {
assert!(element_size >= mem::size_of::<Node>());
assert!(element_size % mem::size_of::<usize>() == 0);
let total_bytes = num_elements
.checked_mul(element_size)
.expect("size overflow when computing total_bytes");
let align = 64usize.max(mem::align_of::<Node>());
let layout = Layout::from_size_align(total_bytes, align).expect("invalid layout");
let ptr = unsafe { alloc_zeroed(layout) };
if ptr.is_null() {
panic!("memory allocation failed");
}
// Optionally advise the kernel about access pattern and lock into RAM to avoid swapping
unsafe {
let _ = madvise(ptr as *mut c_void, total_bytes, MADV_RANDOM);
if mlock(ptr as *const c_void, total_bytes) != 0 {
eprintln!("Warning: mlock failed (continuing anyway). Consider running with privileges or ulimit adjustments.");
}
}
unsafe {
for i in 0..num_elements {
let current_node_ptr = ptr.add(i * element_size) as *mut Node;
let next_idx = (i + 1) % num_elements;
let next_node_ptr = ptr.add(next_idx * element_size) as *mut Node;
ptr::write(&mut (*current_node_ptr).next, next_node_ptr);
}
}
let head = ptr as *mut Node;
Self {
ptr,
layout,
head,
num_elements,
total_bytes,
}
}
fn run_benchmark(&self, warmup_iterations: usize, iterations: usize) -> f64 {
unsafe {
let mut cur = self.head;
for _ in 0..(warmup_iterations * self.num_elements) {
cur = (*black_box(cur)).next;
}
let start = Instant::now();
for _ in 0..(iterations * self.num_elements) {
cur = (*black_box(cur)).next;
}
let elapsed = start.elapsed();
// prevent compiler from optimizing away the traversal
black_box(cur);
let total_steps = (iterations * self.num_elements) as f64;
elapsed.as_nanos() as f64 / total_steps
}
}
}
impl Drop for LinkedListArena {
fn drop(&mut self) {
unsafe {
let _ = munlock(self.ptr as *const c_void, self.total_bytes);
dealloc(self.ptr, self.layout);
}
}
}
fn main() {
const TOTAL_STEPS: usize = 10_000_000;
const WARMUP_ITERATIONS: usize = 2;
let args: Vec<String> = env::args().collect();
if args.len() != 3 {
eprintln!("Usage: {} working_set_2_pow npad", args[0]);
std::process::exit(1);
}
let working_set: usize = args[1].parse().expect("working_set_kb must be an integer");
let npad: usize = args[2].parse().expect("NPAD must be an integer");
let working_set_bytes = 1 << working_set;
let element_size = std::mem::size_of::<Node>() + npad * std::mem::size_of::<usize>();
let num_elements = working_set_bytes / element_size;
if num_elements < 2 {
panic!("Too few elements (num_elements < 2). Try larger working_set_kb or smaller element_stride.");
}
let iterations = (TOTAL_STEPS + num_elements - 1) / num_elements;
let arena = LinkedListArena::new(num_elements, element_size);
let avg_ns = arena.run_benchmark(WARMUP_ITERATIONS, iterations);
let working_set_kb = working_set_bytes / 1024;
println!(
"working_set {}kb, npad:{}: {}ns",
working_set_kb, npad, avg_ns
);
}